Van SQL naar MCP: hoe AI leert praten met je bedrijfssystemen
Eén vraag, vijf stops, vijftig jaar. De reis van SELECT * FROM naar een AI die je boekhouding bevraagt.

De vraag die nooit verandert
Elke ICT-er heeft deze vraag ooit gesteld: “Geef me de tien debiteuren met het hoogste openstaande bedrag.”
Die vraag bestaat zolang er debiteurenbeheer bestaat. In 1988 stelde je hem in SQL. In 2008 via een REST API. In 2024 via een Python-script. En in 2026 zegt een AI-model: “Ik roep even haal_top_openstaande_debiteuren aan.”
De business-vraag verandert nooit. Wat verandert is hoe hij wordt gesteld, wie hem mag stellen, en hoeveel kennis daarvoor nodig is.
In dit artikel neem ik je mee door vijf stops — van directe databasetoegang tot het Model Context Protocol. Niet als theoretisch overzicht, maar vanuit veertig jaar ervaring met ERP-systemen, integraties en de vraag die altijd dezelfde bleef.
De vijf stops in vogelvlucht
Elke stop is een evolutie ten opzichte van de vorige, en elke stop is een antwoord op een probleem dat zijn voorganger had:
- SQL — direct contact met de database, sinds de jaren tachtig
- curl en REST — de database afgeschermd achter een gecontroleerde API-laag
- Python — meerdere API- of SQL-vragen aan elkaar gekoppeld, met logica ertussen
- Tool calling — kant-en-klare functies waaruit een AI kiest
- MCP — een open standaard om die functies aan elke AI-client aan te bieden
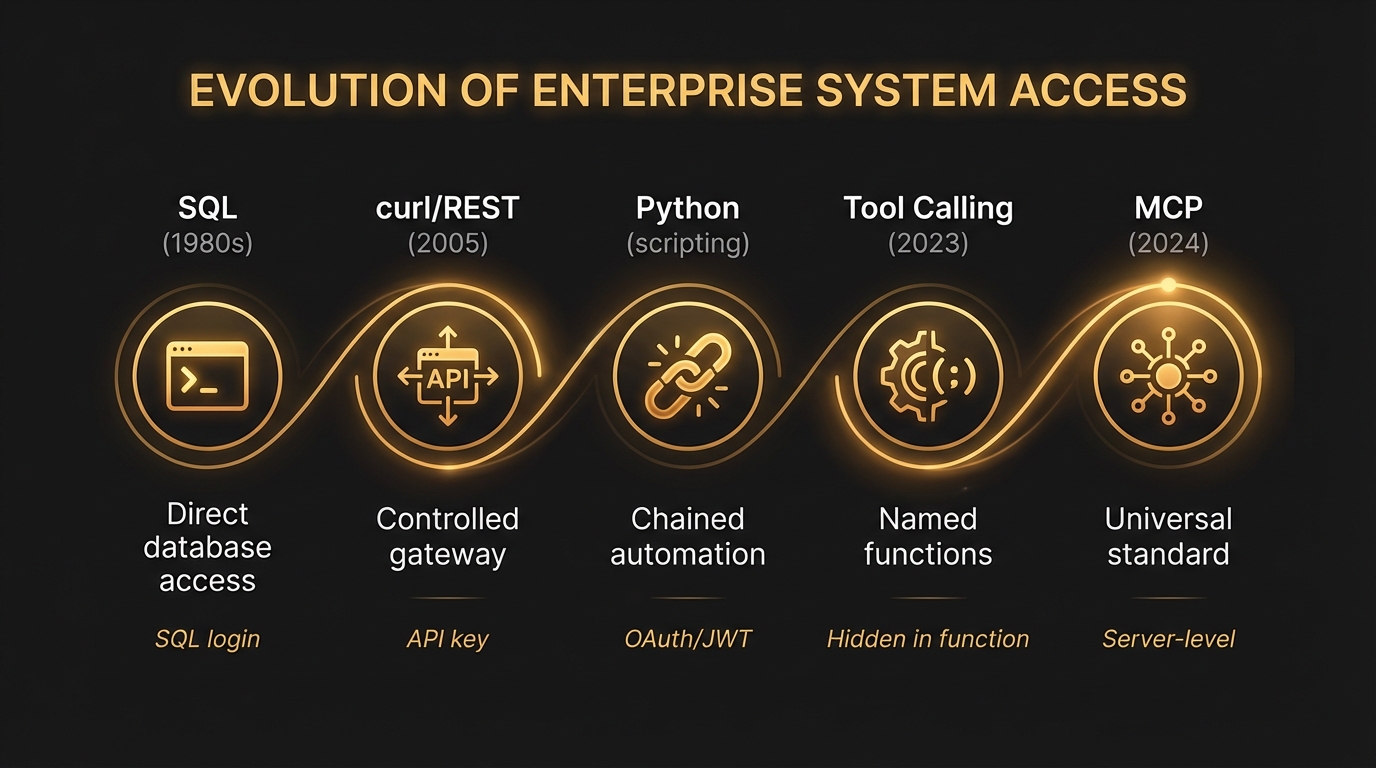
De volgorde is geen menukaart maar een natuurlijke progressie. Tool calling is alleen mogelijk als de vragen die de tools aanroepen al bekend en betrouwbaar zijn. MCP is alleen waardevol als er functies zijn om in te verpakken. Wie de volgorde omdraait, bouwt een verpakking om iets dat nog niet bestaat.
Drie termen die onderweg vallen. REST is de stijl waarin de meeste moderne API’s zijn gebouwd — een afspraak over hoe je vragen stelt. JSON is het formaat waarin die vragen en antwoorden worden ingepakt. XML is JSON’s oudere voorganger — wie ooit een SOAP-koppeling vanuit een ERP-pakket heeft gemaakt, heeft met XML gewerkt. Voor dit artikel hoef je ze niet te kunnen lezen. Het is voldoende om te weten dat REST de afspraak is over hoe de vraag wordt gesteld, en dat JSON of XML het formaat is waarin vraag en antwoord worden ingepakt.
Stop 1 — SQL: het oudste instrument
De vraag, en hoe we hem stelden
Voordat REST API’s gemeengoed werden, was er één manier waarop rapportages en integraties tot stand kwamen: door rechtstreeks vragen te stellen aan de database onder het ERP-pakket. Wie ooit een Crystal Report heeft gebouwd tegen een SQL Server, een dashboard tegen een Exact-database, of een ODBC-koppeling vanuit Excel naar AccountView, heeft precies dit gedaan.
Onze rode-draad-vraag ziet er in SQL zo uit:
SELECT TOP 10
DebtorCode,
Name,
SUM(Amount) AS Openstaand
FROM InvoiceHeader
WHERE Paid = 0
GROUP BY DebtorCode, Name
ORDER BY Openstaand DESC;Wie ooit een rapport in Crystal Reports of Power BI heeft gebouwd, herkent de structuur direct. De complexiteit is beperkt — het zijn afgesproken werkwoorden (SELECT, FROM, WHERE, ORDER BY) gevolgd door tabel- en veldnamen. De rest is logica.
Hoe je binnenkwam
Een SQL-vraag kun je niet stellen zonder toegang tot de database. In de SQL-wereld liep dat via twee methoden:
De eerste is de SQL Server login: een gebruikersnaam en wachtwoord rechtstreeks in de database. Wie dit kent als beheerder, herinnert zich het sa-account — system administrator — waar in de praktijk veel installaties standaard mee werkten, met wachtwoorden die zelden werden geroteerd. Een ODBC-verbinding vanuit Excel of Crystal Reports gebruikte zo’n login, vaak in een DSN-bestand waarin het wachtwoord in platte tekst stond.
De tweede is Windows Authentication: de Windows-account van de gebruiker werd doorgegeven via Active Directory. Netter en veiliger — geen aparte wachtwoorden — maar het werkte alleen binnen Windows-domeinen, en alleen voor mensen, niet voor scripts of cross-domain integraties.
Wie wat mocht zien
Eenmaal binnen, was niet alles toegankelijk. SQL Server bewaakte rechten via twee instructies: GRANT (toegang verlenen) en REVOKE (toegang intrekken). GRANT SELECT ON InvoiceHeader TO ReportingUser zei letterlijk: deze gebruiker mag de tabel lezen, maar niet wijzigen.
Voor meer geavanceerde scenario’s bestond er een techniek die elke DBA kent: stored procedures. In plaats van gebruikers rechtstreeks toegang te geven tot tabellen, werd een procedure geschreven die een specifieke vraag samenstelde. De gebruiker kon zelf de tabel niet zien:
EXEC GetTopOutstandingDebtors @TopN = 10Precies hetzelfde resultaat als de SELECT hierboven, maar zonder dat de aanvrager SQL hoefde te schrijven of een tabel hoefde te kennen.
Een parallel die ertoe doet. Een stored procedure was de eerste, oudste vorm van wat we vandaag een “tool” noemen: een vooraf gedefinieerde handeling met een nette voorgevel en de complexiteit verstopt eronder. In stop 4 komt dit concept terug — in een nieuwe vorm, maar met dezelfde grondgedachte.
De rapportwereld eromheen
Rondom SQL ontstond een heel ecosysteem. Crystal Reports was decennialang de standaard voor financiële rapportages. Excel met ODBC-koppelingen werd het werkpaard van controllers. SQL Server Reporting Services (SSRS, beschikbaar vanaf 2004) bood een server-versie. Power BI is daarvan de moderne opvolger geworden, met dezelfde fundamentele werkwijze: een SQL-query onder de motorkap, een grafische schil eromheen.
Dit is relevant: alles wat in deze tools werd gebouwd, was een handmatig opgebouwde versie van wat vandaag een tool calling-functie zou heten. De vragen die toen werden gesteld, worden nu opnieuw gesteld.
Waarom dit niet meer schaalde
Het SQL-model heeft het vakgebied vier decennia gediend. Maar het had drie problemen:
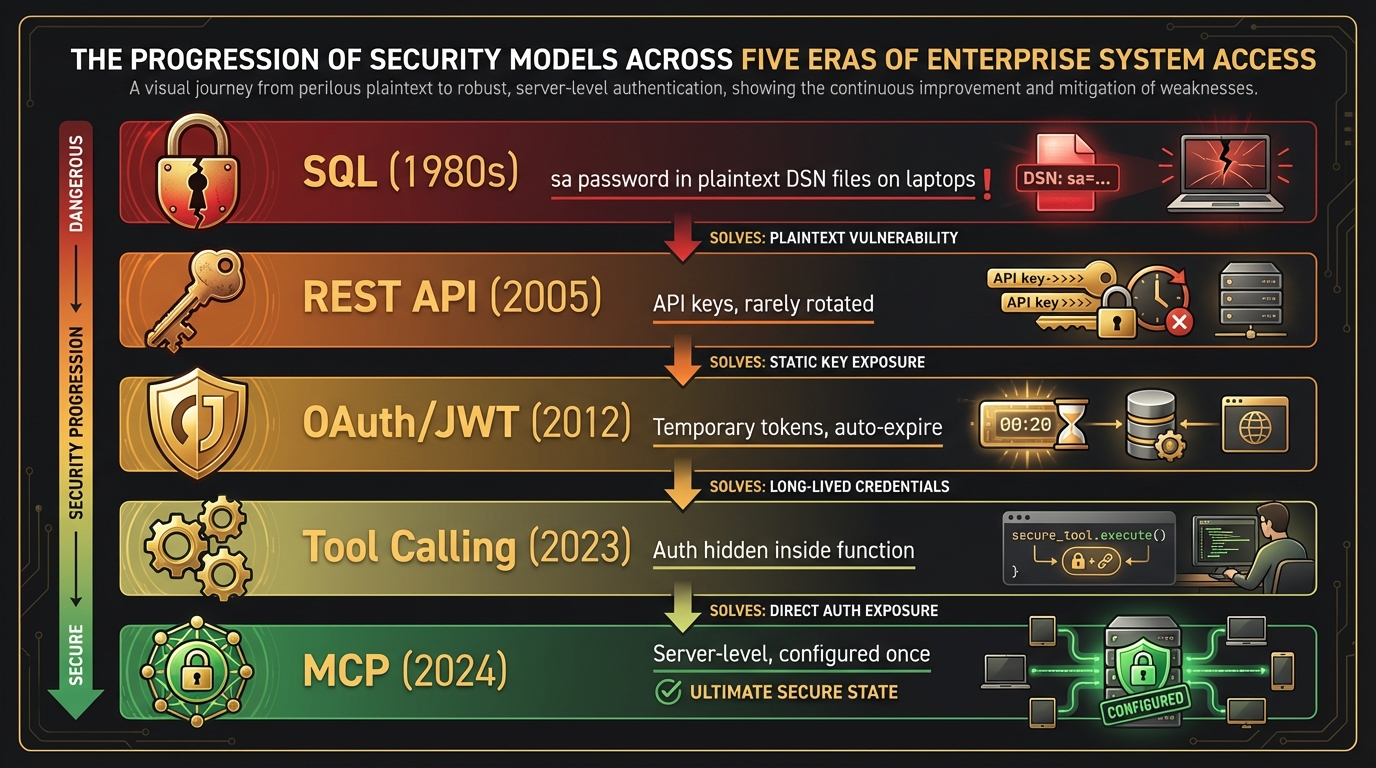
Secrets management. Connection strings met wachtwoorden in platte tekst, sa-accounts die nooit roteerden, DSN-files verspreid over laptops. Eén kwijtgeraakte laptop kon volledige database-toegang opleveren.
Rechten-explosie. Elke nieuwe rapport-gebruiker betekende een nieuwe SQL-login, een nieuwe set GRANT-statements. Bij een organisatie van enige omvang werd dat onbeheersbaar.
Gebrek aan auditing. Wie had welke query gesteld, op welk moment? Behoorlijke ingebouwde audit-mogelijkheden kwamen pas met SQL Server 2008 — en zelfs toen werden ze zelden ingericht.
De ERP-leveranciers hebben in reactie een nieuwe laag boven de database gezet: een API.
Stop 2 — curl en REST: de API als gecontroleerde poort
Dezelfde vraag, maar via een poort
Vanaf halverwege de jaren tweeduizend begonnen ERP-leveranciers een tussenlaag te bouwen. In plaats van directe SQL-toegang kwam er een web API die vragen ontving, valideerde, controleerde wie ze mocht stellen, en pas dan de onderliggende SQL uitvoerde.
Het instrument om zo’n API te bevragen heet curl — een command-line tool die sinds 1998 in elke serieuze IT-omgeving aanwezig is:
curl -X POST https://api.erp-leverancier.nl/Query/OutstandingDebtors \
-H "Authorization: Bearer <access-token>" \
-H "Content-Type: application/json" \
-d '{"Top": 10, "OrderBy": "Amount DESC"}'De inhoud van de vraag is identiek aan die van stop 1. De vorm is anders. En de toegangspoort is anders — en dat is precies waarom deze stop bestaat.
Hoe je binnenkomt — API key, OAuth, JWT
Waar in stop 1 een wachtwoord direct aan de database werd meegegeven, zijn er nu drie vormen van toegang:
API key: een lange reeks tekens die de leverancier eenmalig uitgeeft. Eenvoudig, maar met dezelfde zwakte als het oude sa-wachtwoord — wie de key heeft, heeft alles.
OAuth 2.0 (gestandaardiseerd als RFC 6749 in 2012): een flow waarin de gebruiker zich authenticeert en de leverancier een tijdelijk access token uitgeeft. Scripts kunnen werken zonder dat ze ooit een wachtwoord zien.
JWT (JSON Web Token): een token die zelf gestructureerde informatie bevat over wie de gebruiker is, wat hij mag, en tot wanneer. Dit is wat moderne API’s gebruiken.
Het verschil met stop 1 is fundamenteel. Wachtwoorden hoeven niet meer in INI-bestanden te staan. Tokens kunnen worden ingetrokken. Auditing is standaard ingebouwd. Drie van de drie problemen uit stop 1 zijn in principe opgelost.
Wat de API niet automatisch oplost
De API-laag heeft veel verbeterd, maar ze heeft ook nieuwe problemen geïntroduceerd. Documentatie blijft achter op werkelijk gedrag. Velden heten anders dan in de database. Endpoints gedragen zich anders dan beloofd. Foutmeldingen zijn vaag.
Bij een recente ERP-integratie heb ik in de eerste werkdag 35 afwijkingen van de documentatie vastgelegd, waarvan vier fundamenteel: een endpoint die zegt te valideren maar niets controleert, een endpoint die bedragen stilzwijgend weggooit, refresh tokens die ongedocumenteerd roteren, en filters die bij een typo willekeurige rijen retourneren.
De overgang van stop 1 naar stop 2 is geen pure verbetering. Het is een ruil: oude problemen opgelost, nieuwe geïntroduceerd.
Stop 3 — Python: de keten die met beide werelden praat
De eerste twee stops zijn vormen van direct contact: met een database, of met een API. Stop 3 is een laag die er bovenop komt en met beide werelden tegelijk werkt.
Python op de REST API
Zodra een API meer dan één stap nodig heeft, wordt curl onhandig. Bij een moderne API loopt authenticatie via meerdere stappen: eerst inloggen, dan een token ophalen, die meegeven bij elke vraag, en bij verlopen opnieuw refreshen.
In Python staat die keten in enkele regels:
import requests
# Stap 1 — inloggen, token ophalen
resp = requests.post('https://api.erp-leverancier.nl/login',
json={'Username': USERNAME, 'Password': PASSWORD})
token = resp.json()['token']
# Stap 2 — de eigenlijke vraag stellen
debtors = requests.post(
'https://api.erp-leverancier.nl/Query/OutstandingDebtors',
json={'Top': 10, 'OrderBy': 'Amount DESC'},
headers={'Authorization': f'Bearer {token}'}).json()
print(debtors)Vier instructies. Inloggen, token ophalen, vraag stellen, resultaat tonen.
Python op de database
Hetzelfde principe werkt voor stop 1. Python bevraagt databases via libraries zoals pyodbc of psycopg2:
import pyodbc, os
conn = pyodbc.connect(
'DRIVER={SQL Server};'
f'SERVER={os.environ["DB_HOST"]};'
f'DATABASE={os.environ["DB_NAME"]};'
f'UID={os.environ["DB_USER"]};'
f'PWD={os.environ["DB_PASS"]}'
)
cursor = conn.cursor()
cursor.execute("""
SELECT TOP 10 DebtorCode, Name, SUM(Amount) AS Openstaand
FROM InvoiceHeader
WHERE Paid = 0
GROUP BY DebtorCode, Name
ORDER BY Openstaand DESC
""")
for row in cursor.fetchall():
print(row)Conceptueel niet anders dan een Crystal Report via ODBC. Het verschil: credentials komen uit environment variables, niet uit een DSN-bestand op een laptop.
Secrets, env-vars en wat we van stop 1 hebben geleerd
In een moderne Python-werkwijze staan credentials nooit in de code. Ze staan in environment variables die uit een afgeschermd .env-bestand of een centrale geheimenkluis worden geladen. USERNAME = os.environ['USERNAME'] in plaats van USERNAME = "wim".
Python is dus geen ander soort gereedschap. Het is dezelfde vraag, in een vorm die opeenvolgende stappen aan elkaar koppelt, met fatsoenlijk secret management, en met de vrijheid om te kiezen tussen database of API.
Stop 4 — Tool calling: de stored procedure, herboren
De vraag krijgt een naam
In de eerste drie stops moet iemand — mens of AI — bij elke vraag opnieuw bedenken: welke tabel, welk endpoint, welke parameters, welke authenticatie. Dat is goed zolang je het systeem nog leert kennen. Maar zodra vragen routinematig terugkomen, ontstaat er iets fundamenteels:
naam: haal_top_openstaande_debiteuren
beschrijving: Geef de N debiteuren met het hoogste openstaande bedrag
parameters:
- aantal (optioneel, standaard 10)
- peildatum (optioneel, standaard vandaag)Onder de motorkap is dit een Python-functie die hetzelfde HTTP-verzoek of SQL-statement uitvoert als in de eerdere stops. Het verschil: alle afspraken die in de verkenning zijn ontdekt — datumformaten, BTW-codes, joins, omgang met API-fouten, token-rotatie — zitten nu in de functie. De aanvrager hoeft er niets meer van te weten.
De parallel met stored procedures
Wie aandachtig heeft gelezen, herkent dit. Een stored procedure in een SQL Server uit 1998 deed precies hetzelfde: een vraag verbergen achter een naam. EXEC GetTopOutstandingDebtors @TopN = 10 toen, en haal_top_openstaande_debiteuren(aantal=10) nu, zijn varianten van hetzelfde idee.
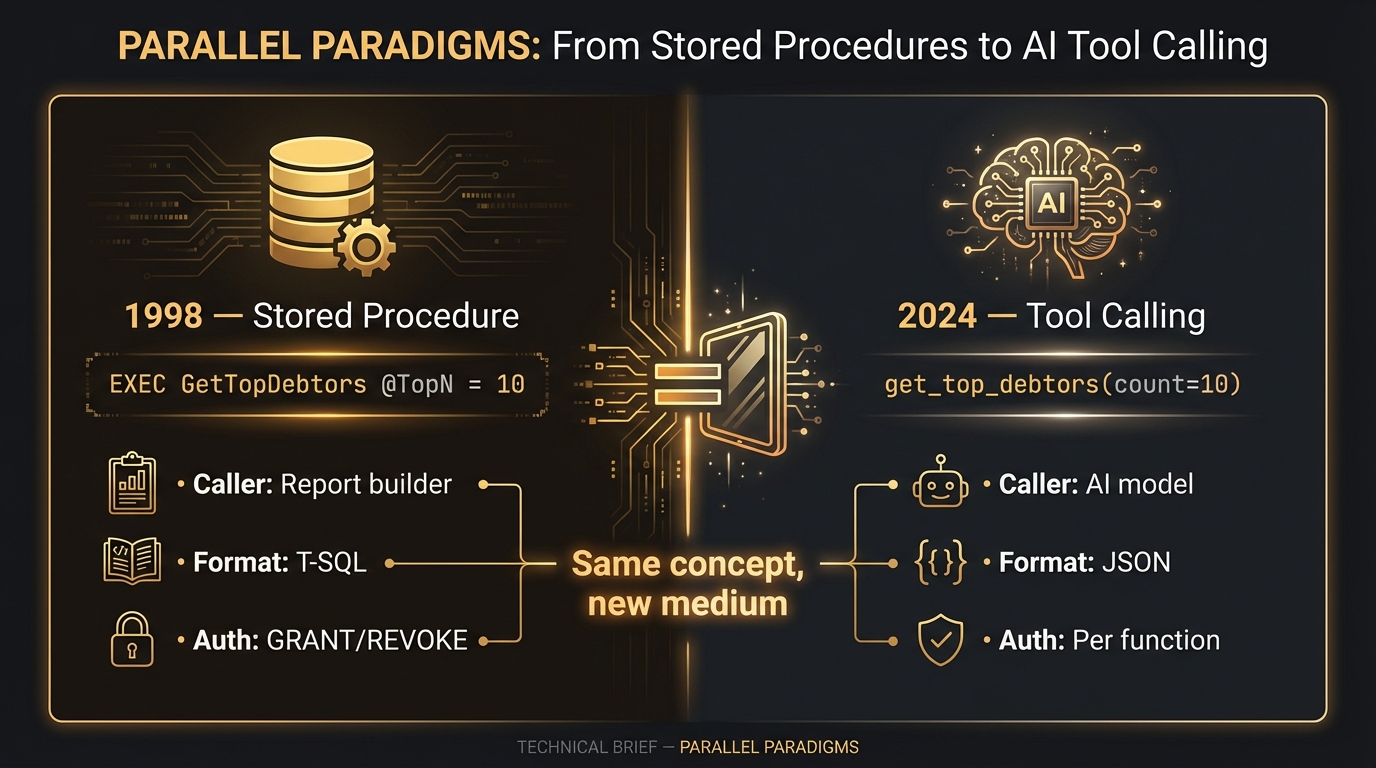
De cirkel is rond. Tool calling is geen nieuw concept. Het is een stored procedure, herboren in een nieuw medium, met de afspraken uitgedrukt in JSON in plaats van T-SQL, en een AI-model als aanvrager in plaats van een rapportbouwer. Wat verandert is het tempo en de schaal. Het wezen is hetzelfde.
Beveiliging — verstopt in de functie
De auth-flow die in stop 3 expliciet in de code stond, verdwijnt in stop 4 in de functie zelf. De aanvrager hoeft niet meer te weten dat er een token bestaat. Als de token verlopen is, vraagt de functie zelf een nieuwe op.
Rechten worden niet meer beheerd op tabel- of endpoint-niveau, maar op functieniveau. “Mag deze gebruiker haal_top_openstaande_debiteuren aanroepen?” is een veel kleinere, veel beter beheersbare vraag dan “mag deze gebruiker de tabel InvoiceHeader lezen?”.
Stop 5 — MCP: de gestandaardiseerde verpakking
Een server om de functies aan iedereen aan te bieden
Tot hier is alles bruikbaar voor één persoon of één applicatie. De functies van stop 4 werken binnen het project waarin ze geschreven zijn, maar ze zijn niet zomaar bruikbaar in een ander project, een andere AI-client, of door een collega.
Die standaard heet sinds november 2024 MCP — het Model Context Protocol, gepubliceerd door Anthropic en sindsdien geadopteerd door OpenAI, Google, GitHub, Atlassian, en tientallen andere partijen.
Een MCP-server is een klein zelfstandig programma dat tegen elke compatibele client zegt: “Ik bied de volgende functies aan, hier zijn hun namen, hun parameters, en dit is wat ze doen.” Onze rode-draad-vraag wordt verpakt in een MCP-server en is daarna beschikbaar in Claude Desktop, Claude Code, Cursor, VS Code met GitHub Copilot, en in toenemende mate andere clients — zonder dat een van die clients iets hoeft te weten van de onderliggende API of database.
Hoe inloggen er nu uitziet
De auth-flow verhuist naar de configuratie van de MCP-server zelf. De server krijgt eenmalig credentials ingericht en bedient vervolgens alle aangesloten clients. Waar in 1998 elke nieuwe rapport-gebruiker een SQL-login en GRANT-statements vereiste, kan in 2026 een hele organisatie worden bediend door één MCP-server die centraal wordt beheerd.
Wat MCP wel en niet doet
MCP voegt geen capability toe die zonder MCP onmogelijk zou zijn. De rode-draad-vraag kan al beantwoord worden via SQL, curl, Python en tool calling. Wat MCP toevoegt:
- Standaardisatie — elke MCP-compatibele client begrijpt elke MCP-server, zonder maatwerk
- Herbruikbaarheid — de server wordt eenmaal gebouwd en is daarna overal inzetbaar
- Geen vendor lock-in — MCP is een open standaard, geen afhankelijkheid van één AI-leverancier
Wat MCP niet doet: kennis bouwen. Een lege MCP-server is leeg. Een MCP-server voor een gebrekkige API is een wikkel om iets gebrekkigs. De waarde komt volledig uit de functies die erin zitten — en die komen uit de kennis van stop 1 tot en met 4.
MCP is voor AI-toegankelijke functies wat de gestandaardiseerde scheepscontainer is voor wereldwijde logistiek. De container heeft de wereldhandel niet uitgevonden — goederen werden al duizenden jaren vervoerd. Wat de container veranderde is de moeite waarmee een lading van het ene transportmiddel op het andere kan worden overgezet. De vraag “willen we MCP?” is vergelijkbaar met “willen we containers?”. Het antwoord hangt af van de vraag of er goederen zijn om te vervoeren.
De vijf stops in één overzicht
| Stop | Periode | Inloggen | Beveiligingsmodel | Wie kan ermee werken |
|---|---|---|---|---|
| 1 — SQL | jaren 80 – heden | SQL Server login of Windows Auth | GRANT/REVOKE, stored procedures | DBA’s, rapportbouwers |
| 2 — curl/REST | ~2005 – heden | API key → OAuth → JWT | Scopes, rate limits, audit-logging | Developers met API-toegang |
| 3 — Python | jaren 90 – heden | Token-rotatie of env-vars | Secrets management, werkt op stop 1 én 2 | Developers, automatisering |
| 4 — Tool calling | 2023 – heden | Verstopt in de functie | Per functie gevalideerd | AI-modellen en applicaties |
| 5 — MCP | eind 2024 – heden | Op server-niveau, eenmalig | Per tool, gedeeld over alle clients | Elke MCP-compatibele client |
Uit de praktijk: drie systemen, drie plekken in de reis
Verschillende systemen kunnen op verschillende plekken in deze reis zitten. Dat is geen probleem — het is precies hoe het hoort.
Een boekhoudsysteem waar ik deze week mee begon, zit op stop 2 en 3. Curl en Python zijn de juiste instrumenten, omdat we nog niet weten welke functies stabiel genoeg zijn om in te verpakken. In de eerste werkdag documenteerde ik 35 afwijkingen van de API-documentatie. Een MCP-server zou hier voorbarig zijn.
Een ERP-connector waar ik maanden aan heb gebouwd, zit op stop 5. De MCP-server heeft 53 tools in 8 categorieën, verwerkt facturen met 97% nauwkeurigheid voor €0,008 per document, en heeft 200+ traces in productie. Dat is de juiste verpakking — niet omdat MCP modieus is, maar omdat de inhoud die erin zit het verdient.
Een derde systeem zit nog vóór stop 1: de kennis is aanwezig, maar zit in hoofden van consultants en developers, niet in expliciete code. Voor onderdelen waarvoor directe SQL-toegang beschikbaar is, is dat het natuurlijke startpunt — niet curl, en zeker niet MCP.
De les
De vraag is niet “willen we MCP?”. De vraag is: “Willen we de kennis die nu in hoofden zit, en die we al twintig jaar in losse rapporten en losse integraties verstoppen, verplaatsen naar systemen?”
Het antwoord op de eerste vraag volgt vanzelf uit het antwoord op de tweede.
De vijf stops vormen geen menukaart. Ze vormen een natuurlijke volgorde die bij elke serieuze ontsluiting van een systeem terugkomt. Eerst leren hoe een systeem werkt met de meest eerlijke instrumenten die er zijn. Dat leren vastleggen in herbruikbare functies. En pas dan die functies in een gestandaardiseerde verpakking aanbieden.
Wie de volgorde omdraait, bouwt iets dat in productie omvalt. Wie de eerste stap overslaat, verpakt een lege koffer.
Dat is geen technische voorkeur. Het is een wetmatigheid — en iedereen die ooit een Crystal Report tegen een ERP-database heeft gebouwd, heeft de eerste stop al een keer doorlopen. De vragen die toen werden gesteld zijn dezelfde als de vragen die een AI nu stelt. Wat erbij komt is tempo. Wat eraan vooraf gaat is de keuze om kennis dit keer expliciet vast te leggen in plaats van hem in een individueel rapport te laten verdwijnen.
Wim Tilburgs is AI-architect en voorzitter van Stichting Je Leefstijl Als Medicijn. Hij ontwerpt AI-systemen voor zorg en MKB, gepubliceerd in het BMJ en gevalideerd met TNO. Dit artikel is gebaseerd op veertig jaar ervaring met ERP-integraties — van IBM System/36 tot MCP-servers met 53 tools.